
Writeup for Cert.se’s CTF 2025
This is a writeup for CERT-SE’s CTF from 2025.
The goal
Quoted from the CERT-SE site:
In the .zip file below is a network dump (PCAP) that contains a total of ten flags. All of these have the format
ctf[string]orCTF[STRING].
Low hanging fruits
The lowest hanging fruit possible would be any plain text flags in the actual .pcap, so:
$> strings cert-se_ctf2025.pcap | rg -i 'ctf\['
ctf[strings_or_cat?]
We have flag: ctf[strings_or_cat?]
The file is corrupt?!
The very first thing I noticed when I opened the .pcap in Wireshark was an error message:
The capture file appears to be damaged or corrupt. (pcap: File has 16795209-byte packet, bigger than maximum of 262144)
I double checked that I had not done anything stupid when I downloaded the ZIP archive. Also, I found it very unlikely that CERT-SE would provide a broken .pcap by mistake. There must be a flag here.
Each packet in a .pcap starts with a 16-byte header (timestamp, captured length, original length). By walking through those headers and stopping when the captured length (incl_len) was larger than the mentioned maximum, I could pinpoint where parsing fails.
import sys, struct
with open(sys.argv[1], "rb") as f:
gh = f.read(24)
if len(gh) != 24:
sys.exit("not a pcap (too short)")
m = gh[:4]
if m == b"\xd4\xc3\xb2\xa1": end = "<" # LE, usec
elif m == b"\xa1\xb2\xc3\xd4": end = ">" # BE, usec
elif m == b"\x4d\x3c\xb2\xa1": end = "<" # LE, nsec
elif m == b"\xa1\xb2\x3c\x4d": end = ">" # BE, nsec
else: sys.exit("unknown magic")
pkt = 0
while True:
off = f.tell()
hdr = f.read(16)
if len(hdr) < 16:
print("EOF at packet", pkt)
break
ts_sec, ts_usec, incl, orig = struct.unpack(end + "IIII", hdr)
if incl > 262144:
print("Broken:", pkt)
print("offset:", off, "incl_len:", incl, "orig_len:", orig)
break
f.seek(incl, 1)
pkt += 1
Out the other end came:
$> python script.py cert-se_ctf2025.pcap
Broken: 3011
offset: 29102359 incl_len: 16795209 orig_len: 1207959809
So at byte 29 102 359 (package 3011) something starts that is not a regular 16 byte .pcap payload.
$> dd if=cert-se_ctf2025.pcap bs=1 skip=29102359 count=16 2>/dev/null | xxd
00000000: ffd8 ffe0 0010 4a46 4946 0001 0101 0048 ......JFIF.....H
That is likely an image!!
I hoped for the best and went for it:
dd if=cert-se_ctf2025.pcap of=image.jpg bs=1 skip=29102359 status=none
and out the other came:

We have flag: ctf[carve_carve]
Following TCP Streams
My goto from last year (that I figured I’d try again this year) was to simply go through the various TCP streams in the .pcap.
TCP Stream 6
TCP Stream 6 contains some HTTP data. More precisely, an index.html file.
<!DOCTYPE html>
<html lang=sv>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>The sky above the port was the color of television, tuned to a dead channel.</title>
<style>
body {
background-color: black;
margin: 3em;
}
span {
height: 1em;
width: 1em;
background-color: darkgreen;
margin: 1px;
padding: 0;
display: inline-block;
text-align: center;
}
span:nth-of-type(10), span:n-th-of-type(1002), [... a lot of this]
{
background-color: lightgreen;
}
</style>
</head>
<body>
<span></span> <span></span> [a lot of this too]
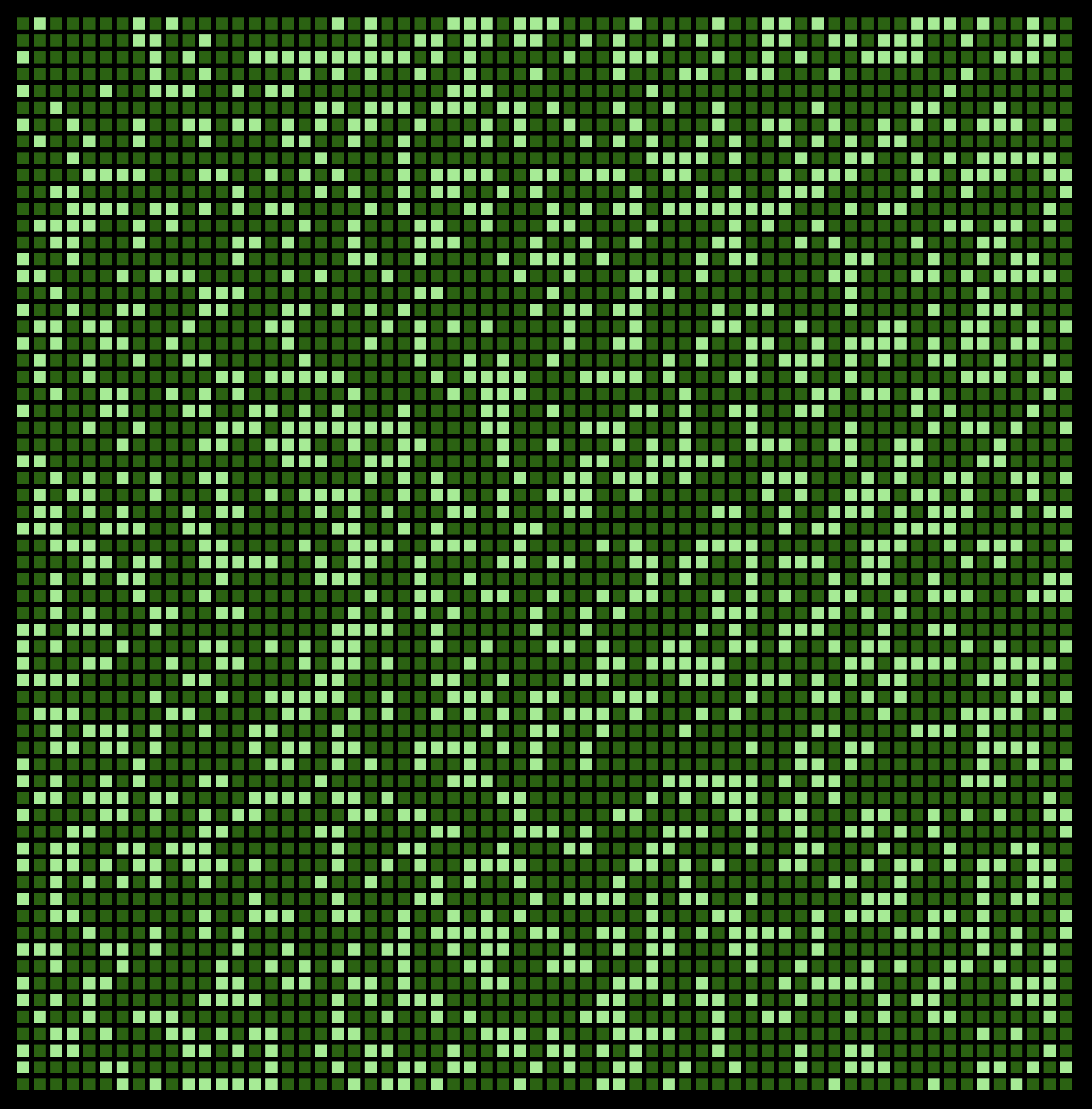
A QR Code?
I don’t read fluent HTML so I just opened the file in my browser instead. The page showed boxes – many boxes – coloured light green and dark green respectively. My immediate idea was to zoom in/out until the boxes re-ordered themselves into a flag. Well, no luck.
Let’s dig deeper
The page also has a title:
The sky above the port was the color of television, tuned to a dead channel.
Which seems to be a quote from Neuromancer, by William Gibson.
Being born in the 90’s, a TV tuned to a dead channel would show “the war of the ants” (black and white, static). Hence, I believe I am actually on to something w.r.t. my QR Code above. At least, I believe, I should be working with the boxes as pixels/binary data.
All the ways to look at pixels
I wrote a Python script to generate as many permutations as I could think about.
- Different widths
- Inversions
- Rotations
- Use odd / even columns / rows in different ways
Nothing yielded an image with a clear CTF[ in it :(
- Think of the data as binary
- Maybe binary + compression?
- zlib
- gzip
- lz4
No bueno.
What about Morse code?
Nope.
Back to the index.html itself
What about looking at only the light green boxes? Is there something with their indices? There seems to be 1 471 light green boxes and 2 625 dark green boxes. 1 471 is prime – is that a hint?!
At this point I moved on.
TCP Stream 7
TCP Stream 7 seems to be the same session (is that the correct nomenclature?) as we saw in Stream 6, but instead of
doing a GET of /index.html it’s a GET of /favicon.ico.
GET /favicon.ico HTTP/1.1
Host: 192.168.122.1:8000
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:143.0) Gecko/20100101 Firefox/143.0
Accept: image/avif,image/webp,image/png,image/svg+xml,image/*;q=0.8,*/*;q=0.5
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
Referer: http://192.168.122.1:8000/index.html
Priority: u=6
HTTP/1.0 404 File not found
Server: SimpleHTTP/0.6 Python/3.12.3
Date: Thu, 25 Sep 2025 14:05:02 GMT
Connection: close
Content-Type: text/html;charset=utf-8
Content-Length: 335
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Error response</title>
</head>
<body>
<h1>Error response</h1>
<p>Error code: 404</p>
<p>Message: File not found.</p>
<p>Error code explanation: 404 - Nothing matches the given URI.</p>
</body>
</html>
I don’t really know what to look for here.
TCP 8
TCP Stream 8 contains an email sent from CTF Tech Support to dear user Nessie, who needs help with her tabs! If we take a look at the data we can find Nessie’s plea for help:
From: hdesk@ctftechsupport.se
To: nessie@loch.com
Subject: RE: I LOST MY TABS??? [Ticket#478291]
--===============0296359107785540648==
Content-Type: text/plain; charset="us-ascii"
MIME-Version: 1.0
Content-Transfer-Encoding: 7bit
Dear Nessie! I have recovered your beloved tabs and you should be able to resume your work,
whatever you are doing. See attachment and follow the guide I gave to you by the dock earlier today.
--===============0296359107785540648==
Content-Type: application/octet-stream
MIME-Version: 1.0
Content-Transfer-Encoding: base64
Content-Disposition: attachment; filename="sessionstore.jsonlz4"
Content-Type: application/octet-stream
bW96THo0MADWUgAA8AF7InZlcnNpb24iOlsic2VzCwDyDXJlc3RvcmUiLDFdLCJ3aW5kb3dzIjpb
eyJ0YWIJAGJlbnRyaWUMAPR9dXJsIjoiYWJvdXQ6aG9tZSIsInRpdGxlIjoiTmV3IFRhYiIsImNh
...
The issue at hand seems simple enough: Decode the base64 encoded text and decompress with LZ4. Out the other ends come browser tab data:
{
"version": [
"sessionrestore",
1
],
"windows": [
{
"tabs": [
{
"entries": [
{
"url": "https://cert.se/#16n4[2t",
"title": "CERT-SE - Sveriges nationella CSIRT",
"cacheKey": 0,
"ID": 15,
"docshellUUID": "{abcd136f-fad2-46b9-a387-683841f7043b}",
"referrerInfo": "BBoSnxDOS9qmDeAnom1e0AAAAAAAAAAAwAAAAAAAAEYAAAAAAAAAAAABAQAAAAABAA==",
"originalURI": "http://cert.se/#16n4[2t",
"resultPrincipalURI": "https://cert.se/#16n4[2t",
"loadReplace": true,
"loadReplace2": true,
"contentType": "text/html",
"principalToInherit_base64": "{\"0\":{\"0\":\"moz-nullprincipal:{228b1ff6-8da2-4570-baf6-aaee44c51321}?http://cert.se\"}}",
"hasUserInteraction": false,
"triggeringPrincipal_base64": "{\"3\":{}}",
"docIdentifier": 17,
"transient": false
}
],
"lastAccessed": 1758129005308,
"hidden": false,
"searchMode": null,
"userContextId": 0,
"attributes": {},
"index": 2,
"requestedIndex": 0,
"image": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAo0lEQVQ4je2TsQ3CMBBF3zFBPAEL4UyQxlvRUSHRh54lWIAmbU6hI1JMgWPZSoTijoJf2b73nyxZFu89AHo1n8XGVIdeAHYlpbX8Bb8meBX0IpsK7gWCyKaCS4EgsqngCHQbyl1gc4Gx+gQaYPxSHoEmsIsbYKzeAAdMK+UJcIGJWTyjsXoGamBIjgegDrMsMn9nEckGfVvtgVPYOmP1kc7n3hthhC5vh/jF6AAAAABJRU5ErkJggg=="
},
{
"entries": [
{
"url": "about:newtab",
"title": "New Tab",
"cacheKey": 0,
"ID": 16,
"docshellUUID": "{260eaf8d-7661-45e2-b43d-b8e932daa87b}",
"resultPrincipalURI": null,
"hasUserInteraction": true,
"triggeringPrincipal_base64": "{\"3\":{}}",
"docIdentifier": 18,
"transient": false
},
{
"url": "https://cert.se/#13t1c3f",
"title": "CERT-SE - Sveriges nationella CSIRT",
"cacheKey": 0,
"ID": 20,
"docshellUUID": "{260eaf8d-7661-45e2-b43d-b8e932daa87b}",
"referrerInfo": "BBoSnxDOS9qmDeAnom1e0AAAAAAAAAAAwAAAAAAAAEYAAAAAAAAAAAABAQAAAAABAA==",
"originalURI": "http://cert.se/#13t1c3f",
"resultPrincipalURI": "https://cert.se/#13t1c3f",
"loadReplace": true,
"loadReplace2": true,
"contentType": "text/html",
"principalToInherit_base64": "{\"0\":{\"0\":\"moz-nullprincipal:{c03e15bd-fdef-4036-8224-de4d2c6cdcff}?http://cert.se\"}}",
"hasUserInteraction": false,
"triggeringPrincipal_base64": "{\"3\":{}}",
"docIdentifier": 24,
"transient": false
}
],
"lastAccessed": 1758129009974,
"hidden": false,
"searchMode": null,
"userContextId": 0,
"attributes": {},
"index": 2,
"requestedIndex": 0,
"image": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAo0lEQVQ4je2TsQ3CMBBF3zFBPAEL4UyQxlvRUSHRh54lWIAmbU6hI1JMgWPZSoTijoJf2b73nyxZFu89AHo1n8XGVIdeAHYlpbX8Bb8meBX0IpsK7gWCyKaCS4EgsqngCHQbyl1gc4Gx+gQaYPxSHoEmsIsbYKzeAAdMK+UJcIGJWTyjsXoGamBIjgegDrMsMn9nEckGfVvtgVPYOmP1kc7n3hthhC5vh/jF6AAAAABJRU5ErkJggg=="
},
<REDACTED DATA - there were a lot more of the same>
}
In this JSON blob there are several tabs for various cert.se domains, each with its unique little snippet appended to
the URL. In the truncated output above the URL https://cert.se/#16n4[2t can be found. Let’s start by extracting all
those snippets.
$> rg -o 'https://cert\.se[^" ]*' out.decoded | uniq | cut -d'#' -f2
16n4[2t
13t1c3f
17]12c5r
6e8u11e
15o7s9r
10r14i
Inspecting the snippets they seem to be indices. They go from 1 to 17 and each number is always succeeded by a character.
16: n
4: [
2: t
13: t
1: c
3: f
17: ]
12: c
5: r
6: e
8: u
11: e
15: o
7: s
9: r
10: r
14: i
Order the characters according to their index, aaaaand:
We have flag: ctf[resurrection]
TCP Stream 9
TCP Stream 9 is a connection between the same two hosts as we saw in TCP Stream 6 and 7. This time, we’re doing a GET
towards /CERT-SE.jpg and we can just fetch the image straight from the body of the response.

This is an English version of the same image we got from the corrupted part of the .pcap. Surely the ctf[ bunch of
pixels ] must be a clue that there’s a flag to be found here?
The slightly tinted, yellow(?) box, with all the coloured pixels contains three rows with [3×20, 3×20, 3×2] pixels
respectively.
Throw everything at it
I tried a couple of different things on the file itself, because I did not want to tackle the colour code thingymajing:
$> strings CERT-SE.jpg | rg -i ctf
no output
$> xxd CERT-SE.jpg | rg -i ctf -A 5 -B 5
0003f480: c398 0088 11f0 88db a7cc 7b9f 7e32 7f9c ..........{.~2..
0003f490: 74ab 93ab 8333 b349 b0fa fe57 7eed c40b t....3.I...W~...
0003f4a0: 87e4 6c2a cf71 a592 b2ef afb4 0281 3113 ..l*.q........1.
0003f4b0: db78 8dbc cb78 8bc5 6629 de5f 6366 2a5a .x...x..f)._cf*Z
0003f4c0: 7d37 1a66 638d 5e51 5cd6 e15b 623b 3708 }7.fc.^Q\..[b;7.
0003f4d0: 9c43 5446 a3dd 6651 3f31 ee7d f8c9 fe71 .CTF..fQ?1.}...q <-- It says CTF here, but I don't think that's important
0003f4e0: d3e6 3dcf bf19 3fce 3a7c c7b9 f7e3 27f9 ..=...?.:|....'.
0003f4f0: c74f 98f7 3efc 64ff 0038 e88b 2382 6b4a .O..>.d..8..#.kJ
0003f500: bb41 a2bb 392c 858a e64b 2e21 1721 8f95 .A..9,...K.!.!..
0003f510: b95b c77d 4d12 5b23 bac1 2099 8981 1881 .[.}M.[#.. .....
0003f520: 1188 8888 8da2 2239 4444 4784 4799 6693 ......"9DDG.G.f.
$> binwalk CERT-SE.jpg
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
0 0x0 JPEG image data, JFIF standard 1.01
The slightly less lazy approach
Then I surrendered and started to look at the colourful grid. Unfortunately, the encoded/coloured area does not include
ctf[], meaning we cannot leverage a known crib for decoding…
My initial idea was that each column corresponds to a character. That is, red pink blue would be the first character,
then green yellow light-blue, etc. I created a colour map accordingly:
| Pixel Colour | Value |
|---|---|
| Red | 1 |
| Green | 2 |
| Yellow | 3 |
| Blue | 4 |
| Light-blue | 5 |
| Pink | 6 |
Using this table for decoding the pixels yields the following:
1 2 3 4 4 5 3 2 1 2 4 5 4 5 4 5 2 3 1 2
6 3 4 6 6 1 4 5 3 4 6 1 3 6 6 3 1 4 3 4
4 5 2 1 2 3 6 1 6 5 2 3 1 2 1 2 5 6 6 5
5 6 6 1 1 2 1 2 1 2 2 3 3 4 6 1 3 2 1 2
1 4 2 3 3 6 3 4 6 3 4 1 2 5 2 3 4 5 3 4
2 3 4 5 4 5 6 5 4 5 5 6 6 1 4 5 6 1 6 5
4 5
6 3
1 2
An initial idea is that the triplet 2 4 5 is the space character (because it’s frequent and reasonably spaced).
Meaning that the above can be rewritten as:
1 2 3 4 4 5 3 2 1 4 5 4 5 4 5 2 3 1 5 6 6 1 1 2 1 1 2 3 3 4 6 1 3 2 1 4 5
6 3 4 6 6 1 4 5 3 6 1 3 6 6 3 1 4 3 1 4 2 3 3 6 3 6 3 1 2 5 2 3 4 5 3 6 3
4 5 2 1 2 3 6 1 6 2 3 1 2 1 2 5 6 6 2 3 4 5 4 5 6 4 5 6 6 1 4 5 6 1 6 1 2
Which in turn would result in a six word flag, each word with these numbers of characters respectively: 9 chars + 9
chars + 7 chars + 2 chars + 8 chars + 2 chars. At this point though, I’m not quite sure how to proceed. Frequency
analysis? The number of characters in four of the words are high, so maybe that’s advantageous?
TCP 10
In TCP 10 Stream 10 we find Nessie again – poor soul.
From: m.a.wetherell@duke.com
To: nessie@loch.com
Subject: Lost your SD card?
--===============7889887308178902226==
Content-Type: text/plain; charset="us-ascii"
MIME-Version: 1.0
Content-Transfer-Encoding: 7bit
Dear Nessie! When I was filming a movie I found a SD card near the Loch Ness.
There was some inscription with your email so I am sending you the data extracted
from the SD card. I hope everything is intact. Regards, Marmaduke
--===============7889887308178902226==
Content-Type: application/octet-stream
MIME-Version: 1.0
Content-Transfer-Encoding: base64
Content-Disposition: attachment; filename="PHOTOS.img"
Content-Type: application/octet-stream
6zyQbWtmcy5mYXQAAgQEAAIAAgCg+CgAIABAAAAIAAAAAAAAgAEp0Wb5qlBIT1RPUyAgICAgRkFU
MTYgICAOH75bfKwiwHQLVrQOuwcAzRBe6/Ay5M0WzRnr/lRoaXMgaXMgbm90IGEgYm9vdGFibGUg
Seems to be base64 encoded data from an SD card.
$> base64 -d out.b64 > out.img
$> file out.img
out.img: DOS/MBR boot sector, code offset 0x3c+2, OEM-ID "mkfs.fat",
sectors/cluster 4, reserved sectors 4, root entries 512, sectors 40960 (volumes <=32 MB),
Media descriptor 0xf8, sectors/FAT 40, sectors/track 32, heads 64, hidden sectors 2048,
reserved 0x1, serial number 0xaaf966d1, label: "PHOTOS ", FAT (16 bit)
$> binwalk -e out.img
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
61440 0xF000 PNG image, 819 x 1227, 8-bit/color RGBA, non-interlaced
61481 0xF029 Zlib compressed data, default compression
Out the other end comes a directory and two files:
_out.img.extracted/
.rw-rw-r-- 0 erik 5 Oct 13:00 F029
.rw-rw-r-- 1.2M erik 5 Oct 13:00 F029.zlib
Maybe I’m just miss understanding binwalk, but I would have expected a PNG image too… so I tried another approach:
$> binwalk --dd='png image:png' out.img
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
61440 0xF000 PNG image, 819 x 1227, 8-bit/color RGBA, non-interlaced
61481 0xF029 Zlib compressed data, default compression
This time I got the result I think(?) I expected.
$> ll _out.img-0.extracted/
.rw-rw-r-- 1.2M erik 5 Oct 13:07 F000.png
.rw-rw-r-- 0 erik 5 Oct 13:07 F029
.rw-rw-r-- 1.2M erik 5 Oct 13:07 F029.zlib
Opening the image we see a cute Loch Ness monster(?), but the image seems a little bit broken.

binwalk worked before, so let’s try again:
$> binwalk -e _out.img-0.extracted/F000.png
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
0 0x0 PNG image, 819 x 1227, 8-bit/color RGBA, non-interlaced
41 0x29 Zlib compressed data, default compression
$> ll _out.img-0.extracted/_F000.png.extracted/
.rw-rw-r-- 0 erik 5 Oct 13:12 29
.rw-rw-r-- 1.2M erik 5 Oct 13:12 29.zlib
It’s the same size as before (1.2M) which leads me to believe we’re just looping around on the same data. I don’t really know though.
TCP 11
This stream contained a file called monstrum_piscis_tres containing 420 lines of data which just looks like garbage:
/+NIxAAAAAAAAAAAAFhpbmcAAAAPAAAA+wAAXWAABggLDhASFBYYHCAiIyYoLC40NTg5PUFFR0lK
TU5UVVhZXF1iZWdpa21xdHZ4en6Cg4aIio6Rk5WXmJucoaOmp6qtsbO1t7m8wMHDxcfKzc7R0tXX
...
VVVVVVVV/+MYxMQAAANIAcAAAFVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
VVVVVVVVVVVVVVVVVVVVVVVVVVVV
Monstrum Piscis Tres -> MP3
$> tr -d '\n' < blob.txt | base64 -d > monstrum_piscis_tres.mp3
$> file monstrum_piscis_tres.mp3
monstrum_piscis_tres.mp3: MPEG ADTS, layer III, v2.5, 32 kbps, 8 kHz, Monaural
Playing back the file you hear a beep and something in the background.
I used SoX to create a spectogram of the file:
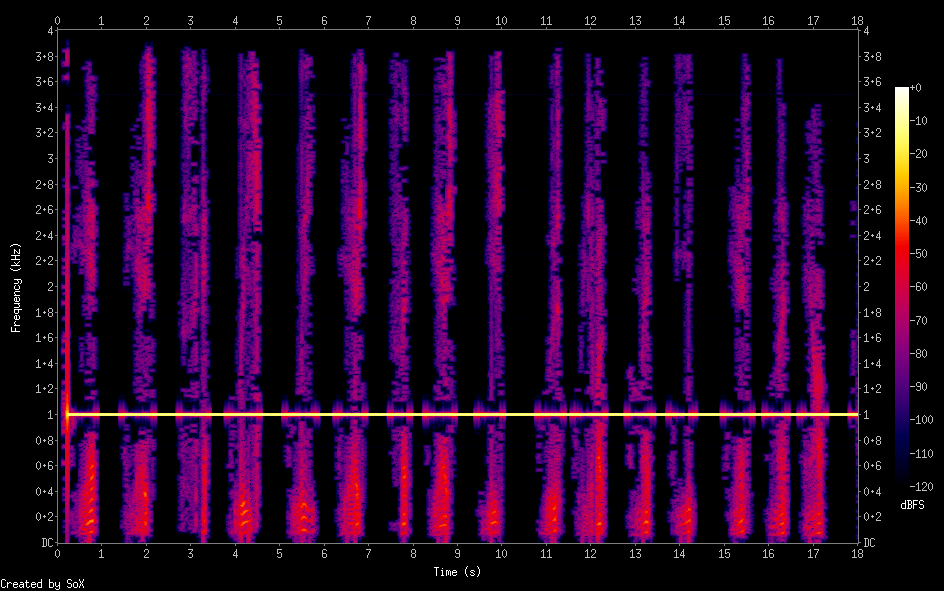
The spectogram clearly shows that there’s a constant tone at 1kHz. I used ffmpeg to remove the constant tone:
$> ffmpeg -i monstrum_piscis_tres.mp3 -af "equalizer=f=1000:width_type=h:width=100:g=-60" no1k.wav
Playing back this file, it’s quite clear that someone is saying something. The voice has that obvious “speaking backwards” sound though, so:
$> ffmpeg -i no1k.wav -af areverse reversed.wav
Playing this back we can hear that someone is reading:
I N K <pause> E M W <pause> 2 G J F J U Q X J A
This matches the Base32 alphabet:
$> echo -n 'INKEMW2GJFJUQXJA' | base32 --decode
CTF[FISH]
We have flag: CTF[FISH]
TCP 12 - 16
TCP Stream 12 shows some communication with an FTP Server. From the succeeding streams it’s possible to extract two files:
ctf.txt
ctf.txt contains these sentences:
If you take the filename excluding the file extension, three letters you know, you have the start of the flag as you know. Maybe you can take, uhm, the last two words in the fourth sentence and make a flag of that, do not forget the characters [] surrounding the flag. You do not have to insert anything between the two words.
Let’s break this down:
If you take the filename excluding the file extension, three letters you know, you have the start of the flag as you know.
This yields: ctf.
Maybe you can take, uhm, the last two words in the fourth sentence and make a flag of that,
This should be: a guess
do not forget the characters [] surrounding the flag. You do not have to insert anything between the two words.
We have flag: ctf[a guess] – I guess?
Ps: If anyone from CERT-SE reads this write-up. Per your recommendation, I tried just dumping the whole text into ChatGPT 5:
Can you find a flag on the format ctf[] or CTF[] in this text?
Capture the Flag (CTF) is more than just a competitive game. It’s a …
and the LLM returned:
Thought for 38s
ctf[a guess]
(From “ctf[” as the filename hint + the last two words of the 4th sentence: “a guess”.)
passwd_policy.txt
It is important to secure and protect our data. This is done using SUPERSECURE passwords. Lucky for us, we have gotten hold of a great password list. The policy is as following:
- Always use passwords from our password list, “rockyou.txt”, you can find it online.
- Do not alter the password from the list.
- Never change your password.
- The shorter the better, so you remember them.
- Always add the flag format surrounding your password.
- When you need to change your password, fill in the password reset form in the lobby of the building.
I’m not quite sure whether this is a red herring or something useful. If I come across an encrypted file, I guess I know where to get my passwords, but I have not found such a file yet.
Following the UDP Streams
Alongside the TCP streams there are 93 UDP streams. They were all quite short so I figured I’d see what ASCII data was extractable from them. I started by converting (is that the right word?) the UDP stream pcap-files to binary data:
mkdir -p streams
for f in *.pcap; do
base="${f%.pcap}"
tshark -r "$f" -Y udp -T fields -e data 2>/dev/null | sed '/^$/d' | while read -r h; do
printf "%s" "$h" | xxd -r -p >> "streams/${base}.bin"
done
done
and then I ran through all files and base64 decoded everything:
$> for i in $(seq 0 92); do
f=streams/udp_stream_${i}.bin
[ -s "$f" ] || continue
base64 -d "$f" 2>/dev/null || true
echo
done
space
5
3
2
2
enter
mouse_1
mouse_1
mouse_1
w
w
w
.
c
e
r
t
.
s
e
enter
mouse_1
scroll_dwn
mouse_1
scroll_dwn
mouse_2
ctrl
c
mouse_1
ctrl
v
mouse_1
c
t
f
[
k
e
y
l
o
g
_
o
v
e
r
_
u
d
p
]
enter
mouse_1
mouse_1
mouse_1
scroll_up
mouse_1
mouse_2
enter
n
e
s
s
i
e
space
i
s
space
n
o
t
space
a
space
m
o
n
s
t
e
r
Did you catch that?!
c
t
f
[
k
e
y
l
o
g
_
o
v
e
r
_
u
d
p
]
We have flag: ctf[keylog_over_udp]